
Understanding High Availability in AWS Databases
High availability (HA) ensures your database remains accessible and operational even during failures, maintenance, or unexpected issues. AWS provides multiple mechanisms to achieve database high availability with minimal downtime.
What is High Availability?
High availability refers to systems designed to operate continuously without failure for extended periods. In database contexts, HA means:
- Minimal planned and unplanned downtime
- Automatic failover capabilities
- Data redundancy across multiple locations
- Quick recovery from failures
- Consistent performance under various conditions
HA Metrics to Track
- Availability: Percentage of uptime (e.g., 99.99% = 52 minutes downtime/year)
- RTO (Recovery Time Objective): Time to restore after failure
- RPO (Recovery Point Objective): Acceptable data loss window
- MTBF (Mean Time Between Failures): Average operational time
- MTTR (Mean Time To Recovery): Average recovery time
Multi-AZ Deployments for RDS
Amazon RDS Multi-AZ deployments provide high availability and disaster recovery for database instances.
How Multi-AZ Works
- Primary database instance in one Availability Zone
- Synchronous replication to standby in different AZ
- Automatic failover in case of failure
- DNS endpoint remains unchanged
- Typically 1-2 minute failover time
Benefits of Multi-AZ
- Protection against AZ failures
- Automatic failover with no manual intervention
- Enhanced data durability
- Maintenance performed on standby first
- Built-in backup capabilities
When Multi-AZ Triggers Failover
- Primary instance failure
- Availability Zone disruption
- Instance type change
- Operating system patching
- Manual failover for testing
Amazon Aurora High Availability Architecture
Aurora’s architecture provides superior high availability compared to traditional databases.
Aurora Cluster Architecture
- One primary instance for writes
- Up to 15 read replicas for reads
- Shared storage layer across all instances
- Storage automatically replicated 6 ways across 3 AZs
- Sub-10-second failover with read replicas
Aurora Auto-Healing Storage
- Continuous backup to Amazon S3
- Point-in-time recovery
- Automatic detection and repair of disk failures
- No data loss from disk failures
- Background scanning and repair
Aurora Global Database
- Primary region for writes
- Up to 5 secondary regions for reads
- Sub-second replication lag
- RPO of 1 second, RTO of 1 minute
- Disaster recovery across regions
DynamoDB High Availability Features
DynamoDB is designed for high availability out of the box with no configuration required.
Built-in Availability
- Automatic multi-AZ replication
- Three copies across different AZs
- Serverless with no instances to manage
- Continuous backups and point-in-time recovery
- 99.99% availability SLA (99.999% for global tables)
DynamoDB Global Tables
- Multi-region, multi-primary database
- Active-active replication
- Sub-second replication between regions
- Automatic conflict resolution
- Ideal for globally distributed applications
Read Replicas for Scalability and Availability
Read replicas distribute read traffic and provide failover options.
RDS Read Replicas
- Asynchronous replication from primary
- Up to 5 read replicas per primary
- Can be promoted to standalone database
- Cross-region replication supported
- Reduces load on primary instance
Aurora Read Replicas
- Up to 15 replicas in same cluster
- Share same storage as primary
- Minimal replication lag (typically milliseconds)
- Automatic failover priority
- Custom endpoints for workload routing
Database Connection Management
Proper connection management is crucial for high availability.
Connection Pooling
- Reduces connection overhead
- Improves application performance
- Handles connection failures gracefully
- Recommended: Use Amazon RDS Proxy
Amazon RDS Proxy
- Fully managed database proxy
- Connection pooling and sharing
- Reduces database connection overhead
- Improves failover time by 66%
- Maintains connections during failover
Backup Strategies for High Availability
Regular backups ensure data recovery in disaster scenarios.
Automated Backup Configuration
- Enable automated backups with appropriate retention
- Schedule during low-traffic periods
- Use point-in-time recovery when needed
- Test restoration procedures regularly
Cross-Region Backup Replication
- Copy automated backups to different region
- Protection against regional disasters
- Compliance with data residency requirements
- Enables cross-region disaster recovery
Monitoring and Alerting for Database Health
Proactive monitoring detects issues before they impact availability.
Key Metrics to Monitor
- Database connections
- CPU and memory utilization
- Disk I/O and throughput
- Replication lag
- Failed login attempts
- Query performance
CloudWatch Alarms for Databases
- Set thresholds for critical metrics
- Configure SNS notifications
- Automate responses with Lambda
- Create custom dashboards
- Use CloudWatch Insights for log analysis

Implementing Database Failover Testing
Regular failover testing validates your HA configuration.
Failover Testing Best Practices
- Schedule regular failover drills
- Test during non-peak hours
- Document failover times and issues
- Verify application handles failover gracefully
- Update runbooks based on test results
Manual Failover Procedures
- Use AWS Console or CLI to initiate
- Monitor application logs during failover
- Verify DNS propagation
- Check data consistency post-failover
- Measure actual RTO against target
Network Design for High Availability
Proper network architecture supports database availability.
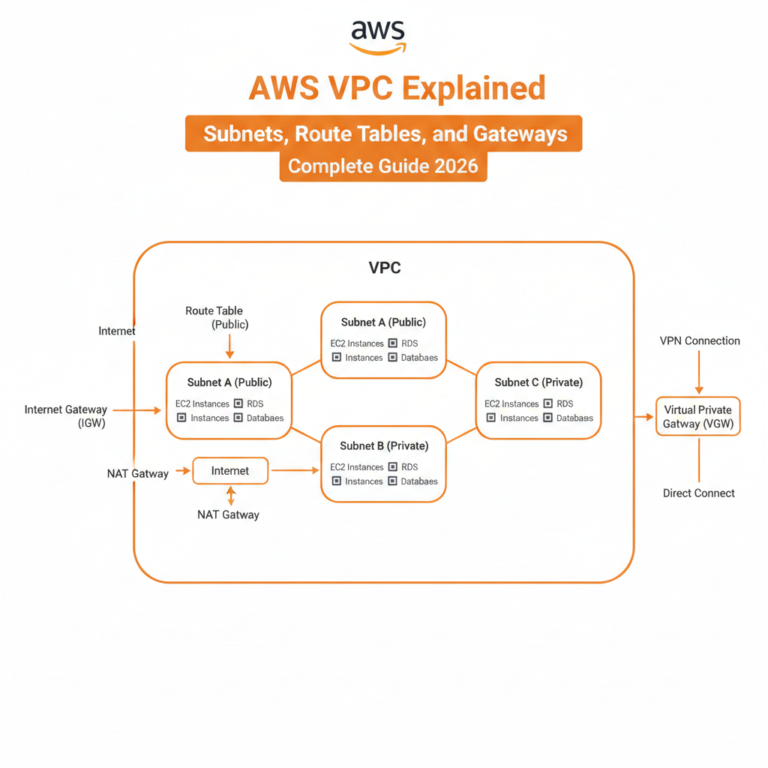
VPC Configuration
- Spread database subnets across multiple AZs
- Use private subnets for database tier
- Implement security groups with least privilege
- Configure NACLs for additional security layer
DNS and Endpoint Management
- Use Route 53 for DNS management
- Configure health checks
- Implement failover routing policies
- Monitor DNS query metrics
Aurora Serverless for Variable Workloads
Aurora Serverless automatically scales capacity based on application needs.
Serverless Benefits for HA
- No capacity planning required
- Automatic scaling during traffic spikes
- Pay only for resources used
- Built-in high availability
- Ideal for intermittent workloads
Serverless v2 Improvements
- Fine-grained scaling (0.5 ACU increments)
- Instant scaling with no interruptions
- Support for all Aurora features
- Read replica scaling
Cost Optimization Without Sacrificing Availability
Balance high availability with cost efficiency.
Cost-Effective HA Strategies
- Use Multi-AZ only for production databases
- Leverage read replicas for scaling instead of larger instances
- Consider Aurora Serverless for variable workloads
- Implement automated start/stop for non-production databases
- Use Reserved Instances for predictable workloads
Disaster Recovery vs High Availability
Understanding the distinction helps plan appropriate solutions.
High Availability
- Prevents downtime from common failures
- Automatic failover within same region
- Minimal data loss (seconds)
- Lower cost, faster recovery
Disaster Recovery
- Protection from catastrophic regional failures
- Manual or automated cross-region failover
- Longer recovery times (minutes to hours)
- Higher cost but comprehensive protection
Conclusion: Building Resilient Database Architectures
Designing highly available databases on AWS requires combining multiple strategies: Multi-AZ deployments, read replicas, automated backups, monitoring, and regular testing. Start with business requirements for availability, then implement appropriate AWS features to meet those requirements.





Leave a Comment